Why?
PyTorch is a phenomenal piece of software. In the midst of the current AI craze, it’s easy to lose sight of the really cool lower-level components that make modern ML possible. I decided to reimplement a basic version of PyTorch with support for strided tensors on CUDA and CPU, and autograd, the automatic differentiation core that enables users to easily run backpropagation.
I’ve also been looking for a good opportunity to learn more Rust and make something cool with it. Rust’s excellent tooling, macro system, and speed make it an excellent candidate to replace the C++ backend in this project. Its thorns (*cough* borrow checker *cough*) provide an interesting challenge. This tutorial will be both an intermediate level explanation of how PyTorch works and an intermediate exploration of the Rust programming language.
(Strided) Tensors
Representing Tensors with arbitrary dimensions and arbitrary shapes seems like a difficult problem at first glance, but its solution is actually quite elegant and intuitive. PyTorch and similar scientific computing packages like NumPy use strided tensors, which are essentially views on top of a piece of (optionally) shared memory. A strided tensor has five properties, and these will be the starting place of our own implementation:
- Storage: A struct containing the exact memory address and length to a piece of allocated memory.
- Shape: A small array that describes the number of elements in each dimension of the tensor
- Stride: A small array that describes the number of elements to skip when iterating over each dimension
- dtype: An enum indicating what datatype is contained in the Tensor. This could be
float32, along, or even abfloat16. - Offset: Where to begin reading from the Storage.
The stride is what makes this, to me, quite magical. Let’s use an example of a three by three matrix represented in memory. Here, you’d have nine total elements. Let’s assume this is a 2d stack-array, and that all nine elements are stored sequentially in memory. The difference between having a 3x3 matrix and a flat nine element array is just a difference in interpretation. For this example, let the backing flat array be called storage.
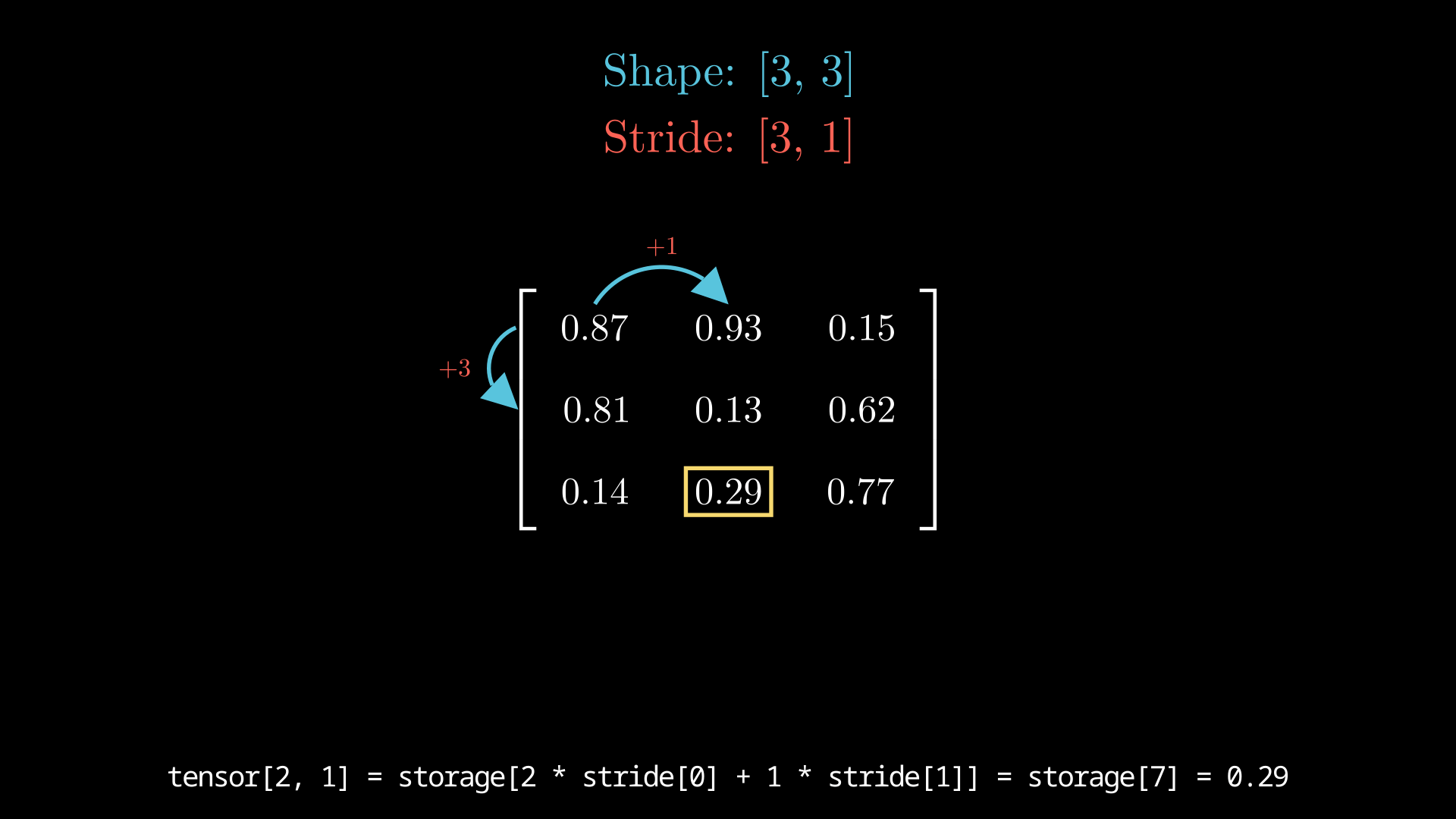
Then, we just use the stride array to properly index through this flat storage array. This makes sense if you’ve ever worked with 2d-arrays in almost any programming language.
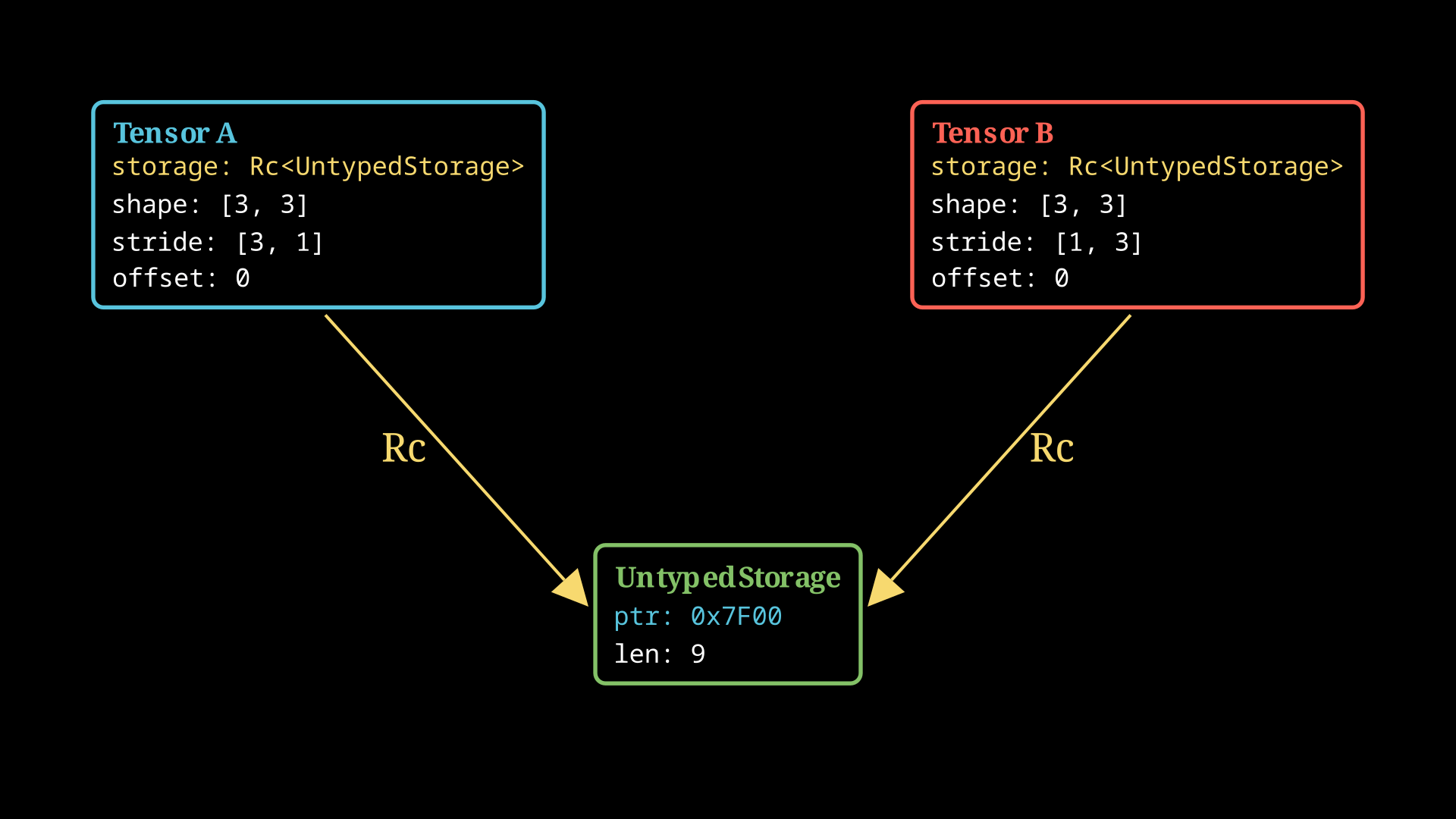
We can manipulate the stride array and create different views on the same flat array. Consider tensor.t(), which returns the transpose of the tensor. We could create a new backing array and copy them over to create this matrix. Or, we could just copy a pointer to the same array and modify the stride array as illustrated. Creating new views from indexes requires creating new offsets and shape vectors rather than fully allocating a new Tensor.

Consider some operations that are actually quite simple like .unsqueeze(), .squeeze(), or .view(). None of these actually requires the mutation of the underlying data, and they can be accomplished by creating a new modified shape, stride, or offset.
NonNull<u8> and Rc
To accomplish this, we will decouple the Tensor from the underlying memory. We’ll need to build two structs: one for maintaining the underlying raw storage, and the actual tensor holding the stride, shape, and type information. We want to enable many tensors to point to the same raw storage container. Rust’s alias rules disallow multiple &mut references to the same struct. More formally, the Rust aliasing rules allow a single mutable reference or multiple immutable references, exclusively. This type of shared, multiple ownership isn’t allowed by aliasing alone.
The solution is to use a reference counter or Rc<T>, which brings back reference counting for a specified object, and automatically drops the inner struct once the reference count hits zero.
Additionally, we’ll use a NonNull<u8> instead of a *mut u8, which enables some nice compiler optimizations at the expense of some type shenanigans. Because we will treat the underlying storage container as untyped storage with raw bytes, we will have to do some unsafe casting.
#[derive(Debug)]
pub struct UntypedStorage {
ptr: NonNull<u8>,
layout: Layout,
n_bytes: usize,
//...
}
#[derive(Default, Debug)]
pub struct Tensor {
shape: Vec<usize>,
stride: Vec<usize>,
offset: usize,
dtype: DataType,
_storage: Rc<UntypedStorage>,
//...
}We’ll make use of the memory allocation API to allocate and deallocate the tensor storage.
impl UntypedStorage {
pub fn with_capacity(bytes: usize) -> Self {
let layout = Layout::array::<u8>(bytes)
.expect("Could not construct layout for UntypedStorage construction!");
UntypedStorage {
ptr: NonNull::new(unsafe { alloc(layout) })
.expect("Could not construct NonNull<u8> with capacity!"),
layout,
n_bytes: bytes,
version: 0,
}
}
pub fn with_capacity_cleared(bytes: usize) -> Self {
let layout = Layout::array::<u8>(bytes)
.expect("Could not construct layout for UntypedStorage construction!");
UntypedStorage {
ptr: NonNull::new(unsafe { alloc_zeroed(layout) })
.expect("Could not construct NonNull<u8> with capacity!"),
layout,
n_bytes: bytes,
version: 0,
}
}
}We also need to implement deallocation behavior that triggers when the storage is dropped by its Rc. In rust, implementing destruction behavior comes from implementing the Drop trait. Side note: If you’re building a storage container and the inner type has properties that require recursive dropping, you’ll have to call that here. I’m making the assumption that we will not need that:
impl Drop for UntypedStorage {
fn drop(&mut self) {
if self.n_bytes == 0 {
return;
}
unsafe {
dealloc(self.ptr.as_ptr(), self.layout);
}
}
}For now we will use Rc<T> over its thread-safe but slower sibling Arc<T>, but a thread-safe implementation will need to use Arc<T>, lest the compiler prevents you from Sending your tensors across threads.
Side note: this is similar to how Vec works under the hood. It uses a Unique wrapper, which has slightly stronger guarantees than a NonNull.
As we see, using the allocation apis requires unsafe, which allows us to momentarily break the compile-time memory safety guarantees that regular rust provides. As we continue to build functionality, we’ll have to be careful to maintain the memory-safety features and contracts through our implementation.
See also (and credits to): Edward Yang’s blog on PyTorch Internals